問題連結: https://leetcode.com/problems/permutations-ii/
題目給予一個可能包含重複數字的數字陣列 nums, 求回傳所有可能的排列
這題是46. Permutations I 的變形題
其實只要對於46題的code稍作修改就可以輕鬆完成這題
以下將簡略帶過46題的解法-
在這題 46. Permutations I 中, 所有數字都保證是不重複的, 因此我們可以直接用backtracking 來解題.
簡單來說, backtracking的idea就是 我們一直需要作選擇, 再根據做的選擇後, 再去做下一個選擇, 直到我們已不能再做選擇, 就會取消我們做的前一個選擇, 改選另一個,… 再繼續 直到我們試過每個可能的選擇組合們
⚠️這裡我將不會仔細地解釋我們 backtracking 的每個步驟 但可以讀我寫的另一篇story 來看我們如何用backtracking來得到數字的組合, 裡面將有我非常詳細step by step的backtracking 過程: Leetcode — 39. Combination Sum(中文)
下圖為我如何用backtracking得到所有可能的數字排列 (假設給予陣列為 不重複數字的[10,20,30]
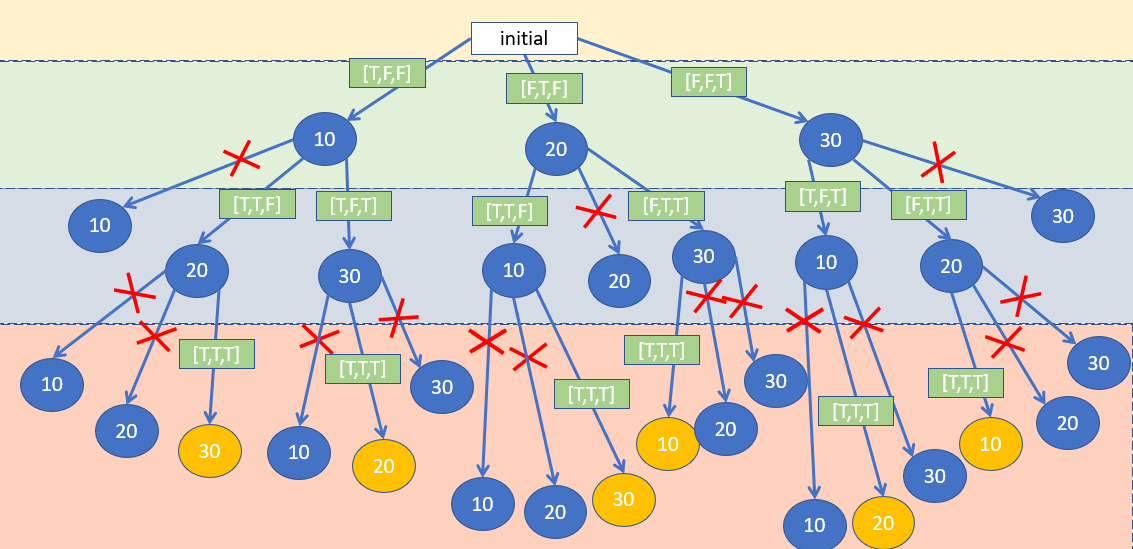
給予的陣列長度是3, 因此我們到每個選擇的地方時都有三個選擇, 決定選擇與否的唯一條件就是看現在所累積的list中有沒有早就加過這個選擇了
為了省時間複雜度, 我們用空間換取時間 - 多用一個boolean array去紀錄 到底有沒有加過某個position的數字 (例如 visited[i] 就代表 我們有無加過nums[i]在此inner list中)
我們知道backtracking 的概念就是 不停地做選擇 再undo redo 再做選擇
所以在這裡, redo的條件就是當我們已選過這個選擇了, 我們就直接回去上一層重選
以下為解決問題46的 1ms 程式碼, 贏過93%:
public List<List<Integer>> permute(int[] nums) {
List<List<Integer>> rst = new ArrayList<>();
helper(rst,nums,new boolean[nums.length],new ArrayList<>());
return rst;
}
public void helper(List<List<Integer>> rst, int[] nums, boolean[] visited, List<Integer> inner){
if(inner.size()==nums.length)
{
rst.add(new ArrayList<>(inner));
return;
}
for(int i=0;i<nums.length;i++)
{
if(visited[i]) //選過這個了 跳過
continue;
inner.add(nums[i]); //決定選擇這個
visited[i] = true; //記得更新我們選擇的紀錄
helper(rst,nums,visited,inner);
inner.remove(inner.size()-1); //已traverse完選了這個選擇後的所有結果了,現在來redo
visited[i] = false; //也要記得更新紀錄 代表我們沒有選擇這個了
}
}而如果我們用同樣的程式碼來求 陣列為[1,2,2]的所有排列
本來期待的答案是: [[1,1,2],[1,2,1],[2,1,1]]
結果我們得到的是: [[1,1,2],[1,2,1],[1,1,2],[1,2,1],[2,1,1],[2,1,1]] 很多長得一模一樣的inner list
那問題來了, 我們要怎麼避免這些討厭又重複的inner list?
最簡單又最懶惰的方式就是 在把inner list加進result list前, 我們先檢查result list有沒有加過一模一樣的inner list 來決定到底要不要把inner list加進result list裡面
但這個問題在於 我們其實浪費時間去蒐集所有可能早就加進去的inner list
有另一個方法則是幫忙加其他的條件 讓我們省下時間不要再理知道最後會白費力氣的選擇們 —
[前提]我們有先把數字排列好順序, 因此一樣數字會聚集在一起
方法: 我們檢查現在位子的數字 是不是跟前一個位置的數字一樣, 如果是的話我們就檢查我們有沒有已經把前一個位子的數字加進陣列了 如果沒有的話 我們就決定捨棄現在的選擇 ….
非常繞口 因此用以下例子來進行解說
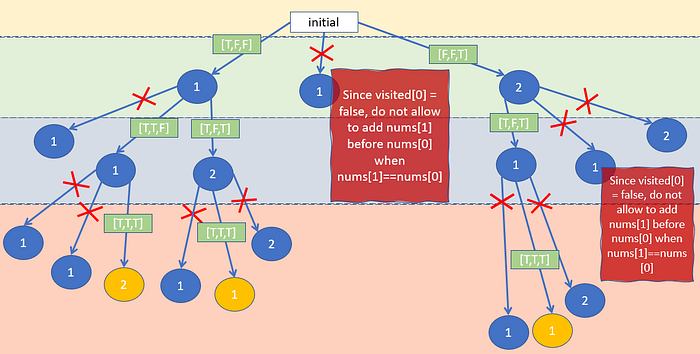
比如我們有一個陣列 [1,1,2], 當我們什麼條件都沒加時, 用backtracking 如下圖:

根據上圖可發現 黃色陰影處跟綠色陰影處的結果是一模一樣
我們從圖可以發現 backtracking的時候 我們把nums[0]的1 跟nums[1]的1'當作不同1, 組合像是[1,1',2] 跟 [1',1,2] 或 [1,2,1'] 跟[1',2,1] 其實都相同
結論是, 我們根本不在乎1跟1'的排列, 因為他們對我們來說就是一模一樣的東西, 所以我們可以針對這個發現來制定一個規則 —
我們不讓1'比1還早出現在排列裡面 我們只接受1比1'先出現的排列們.
⚠️如果我們有三個 或多個1 也是一樣的規則, 總之1就是一定要比其他的1', 1'', 1''' 還先出現; 1'也一定比1'', 1'''... 還早出現, 以此類推
那也就是為何等等程式的判斷會檢查如果此數字是重複數字, 那在他前面的數字有沒有先出現過了, 如果沒有的話 我們不認可現在這個數字比他的"前輩"還早出現.
原本在把inner加進rst前, 用 rst.contains(inner) 來檢查inner list 需要花費241ms
當我們加了我們自己規定的條件後, 現在只要花費 1ms:
public List<List<Integer>> permuteUnique(int[] nums) {
List<List<Integer>> rst = new ArrayList<>();
Arrays.sort(nums);
helper(rst,nums, new ArrayList<>(), new boolean[nums.length]);
return rst;
}
public void helper(List<List<Integer>> rst, int[] nums, List<Integer> inner, boolean[] visited){
if(inner.size()==nums.length)
{
rst.add(new ArrayList<>(inner));
return;
}
for(int i=0;i<visited.length;i++)
{
if(visited[i])
continue;
if(i!=0 && nums[i]==nums[i-1] && !visited[i-1])
continue;
visited[i] = true;
inner.add(nums[i]);
helper(rst,nums,inner,visited);
inner.remove(inner.size()-1);
visited[i] = false;
}
}⚠️不要忘記先sort好陣列,才能保證重複的數字都緊接在一起, 才能套用我們新訂的規則來避免duplicated的排列
時間跟空間複雜度在用backtracking會是指數等級的高 因為我們嘗試著找所有可能的排列
